
Research
Agile Hardware Design
The massive computations of modern applications overwhelm the capabilities of traditional general-purpose processors and call for dedicated hardware. The traditional hardware flow consists of many steps including architecture design, logic synthesis, floorplanning, placement, routing, etc., leading to an extremely lengthy hardware development process. In addition, dedicated hardware require software support including programming languages, compilation tools, libraries, and frameworks. More importantly, both hardware and software designs require low level programming and are difficult to optimize due to the huge design space. Our group proposes Design Automation (DA)driven agile hardware design. The goal is to realize agile hardware design using high-level abstraction, design automation tools, and design space exploration algorithms. In particular, we are tackling the following problems:
- Hardware Generation for Spatial Accelerators
We build dedicated spatial accelerators to accelerate tensor computations. Traditional hardware development starts from handwritten RTL or C-based HLS code. RTL code usually gives the best performance at the cost of long developments and needs to describe every architecture detail. HLS improves the programming productivity but is difficult to optimize. We need a more efficient way to generate hardware.

We generate spatial architectures by building frameworks, generators, and hardware libraries. Specifically, we propose dataflow representation and performance modeling framework using relation-centric notation for spatial architectures [TENET, ISCA’21]. We also develop a hardware generator, which automatically explores various dataflows and generates ASIC or FPGA based accelerators [Tensorlib, DAC’21]. We also propose a hardware library for different convolution algorithms including spatial, Winograd, FFT, and GEMMs on FPGAs [FCNNLib, DAC’20].
- Software Library Generation for Spatial Accelerators
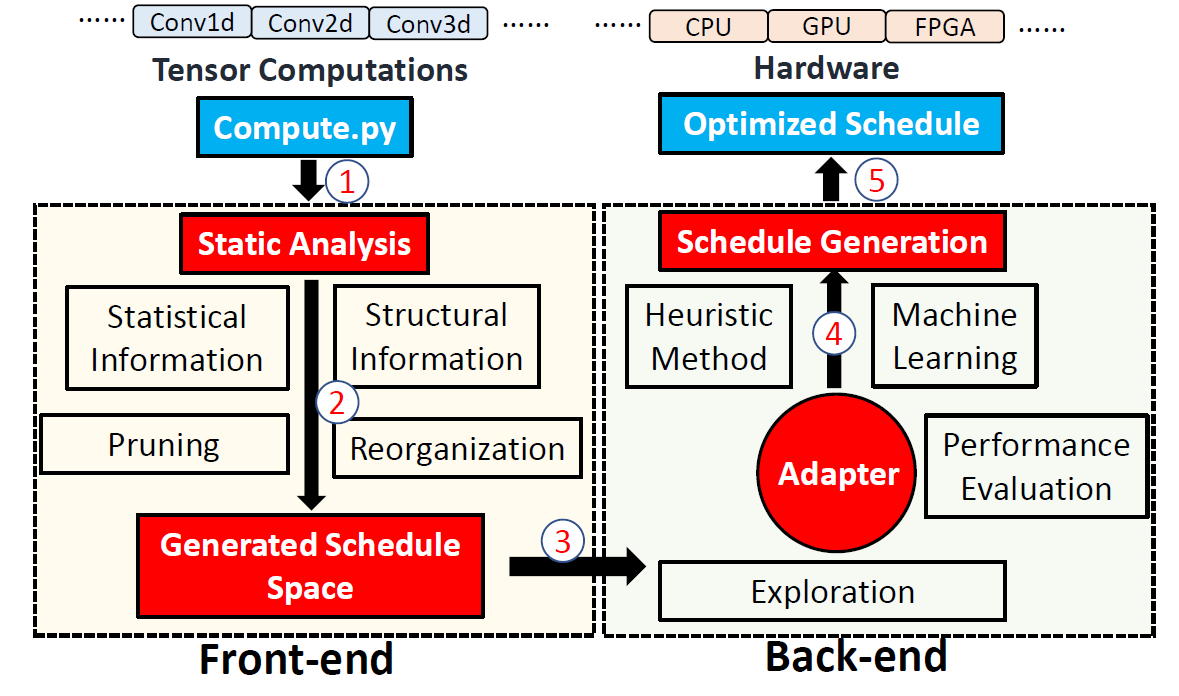
Mainstream applications rely on the library support for compute-intensive operations, such as convolution and matrix multiplication. However, high-performance libraries are difficult and costly to develop and rely entirely on manual design and tuning by programmers. In addition, when programmers optimize libraries, they need to understand the architecture, programming models, and compiler optimizations including loop splitting, loop reorder, vectorization, parallelization, etc. These optimization strategies constitute a huge optimization space, and developers can only explore a limited subset by hand, which usually results in local optimal solutions. Also, emerging hardware, such as CGRAs and brain-inspired chips, require more efforts in application deployments. We develop an exploration and optimization framework, which uses pruning techniques and machine learning techniques to generate high-performance schedules for tensor computation on CPUs, GPUs, FPGAs, and ASICs [FlexTensor, ASPLOS’20].
- HW/SW Co-design for Tensor Computations
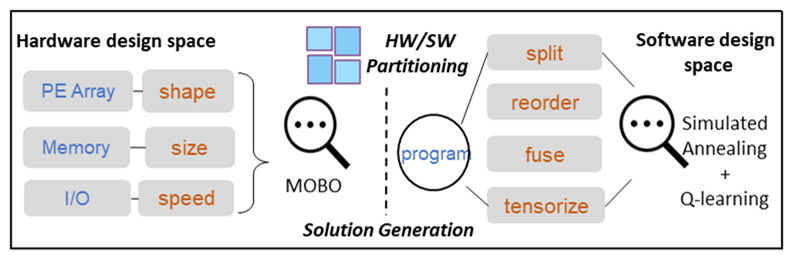
Tensor computation is fundamental for many scientific and engineering applications, such as machine learning, data mining, quantum chemistry. It calls for a combination of hardware acceleration and software mapping. Though dedicated hardware and software optimizations have progressed considerably, they are usually optimized in isolation, leading to sub-optimal solutions confined in a local design space. Hardware/software (HW/SW) co-design can optimize hardware acceleration and software mapping in concert and improve overall performance. However, HW/SW co-design for tensor computations faces two main challenges: 1) how to define the interface between the hardware accelerators and the software programs, 2) how to navigate the huge design space for each part. To address the challenges, we propose an agile co-design framework for tensor computations [HASCO, ISCA’21]. It automatically identifies HW/SW interfaces and explores the huge design spaces with heuristic, Q-learning, and multi-objective Bayesian optimization algorithms. It generates a dedicated chip along with software mappings.
Heterogeneous Computing
While the benefit of heterogeneous systems in clear, the performance optimization and tuning is a heavy lifting task as the programmers need to manually manage the hardware components e.g. cores, reconfigurable logic, cache, register, and shared memory within a single platform, and schedule the workload across the heterogeneous platforms such as FPGAs, GPUs, and CPUs. The heterogeneity in architecture and programming model adds further complexity, which makes it difficult for performance portability.
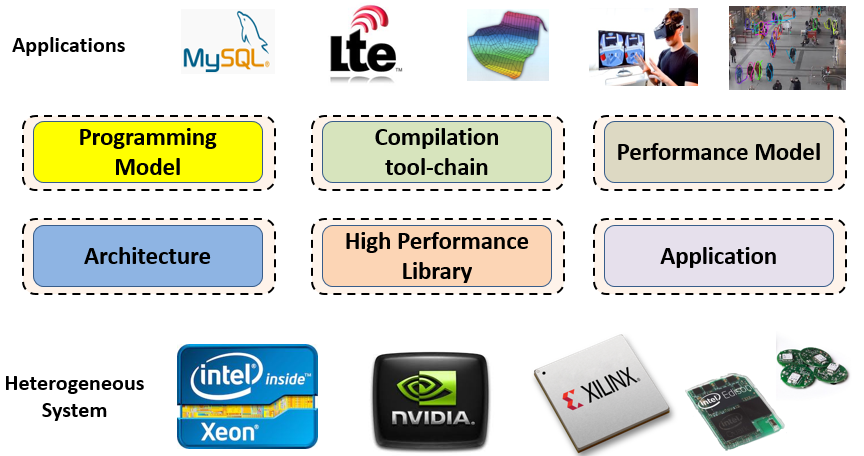
Our group propose a full-stack of hardware and software approaches across algorithm, compiler, and architecture layers to maximize the performance of heterogeneous system. In particular, we are tackling the following problems:
- Architecture Design, Compilation Optimization, and Performance modeling for Heterogeneous System
For a single node, we have designed novel cache bypassing architecture based on the compiler hints (HPCA’15) for GPUs; we have designed novel register allocation algorithm that strikes a balance between single thread performance and thread level parallelism (MICRO’15) for GPUs. For large-scale datacenter, we developed Poly, an OpenCL based heterogeneous system optimization framework that targets to improve the overall throughput scalability and energy proportionality while guaranteeing the QoS by efficiently utilizing GPUs and FPGAs. Poly leverages on compile-time pattern analysis and run-time task scheduler (HPCA’19).
- Machine Learning Application Acceleration using Heterogeneous System.
In general, to deploy a machine learning application, it involves two scenarios: training and inference. Both training and inference are computation-intensive processes, which need high performance heterogeneous computing to support. My research group is investigating efficient hardware and software approaches for the ML applications.
Specifically, we are exploring highly-parallel GPUs for accelerating the training scenario and programmable FPGAs for accelerating the inference scenario. On the GPU side, we have developed parallel algorithms, programming interface, compiler optimization, HPC libraries for ML applications including Matrix factorization (HPDC’17), Image Reconstruction (ICS’18), Latent Dirichlet Allocation (LDA) (HPDC’19). On the FPGA side, we have developed 1) spatial architecture and mapping techniques (DAC’17-systolic, ICCAD’18, DAC’19), 2) fast algorithms for dense and sparse convolutions (FCCM’17, DAC’18, FCCM’19), 3) co-design solutions for specific applications including LSTM and Yolo (FPGA’18, FPGA’19), 4) tool-chains including automated deployment tools and an efficient library that assembles different convolution algorithms (DAC’17, ICCAD’19). We are also among the first to use systolic array architecture and fast algorithms for accelerating DNNs on FPGAs (DAC’17-systolic, best paper nomination, FCCM’17).